Do, 16.08.2018 - 10:38 — Norbert Bischofberger 
![]()
Auf dem Weg zu einer Medizin von Morgen werden wir Zeuge einer der aufregendsten Entwicklungen, deren Ziel es ist Künstliche Intelligenz in biomedizinischer Forschung, Diagnose und Therapie einzusetzen. Vorerst skeptisch, ist der Chemiker Norbert Bischofberger (ehem. Forschungsleiter des Top Pharmakonzerns Gilead, jetzt Präsident des Startups Kronos Bio) nun überzeugt, dass Künstliche Intelligenz die heutige Medizin revolutionieren wird: von der gegenwärtigen Form, die erst reagiert, wenn etwas "passiert" ist, zu einer proaktiven, d.i. voraus schauenden Form, die Risiken vorher erkennt und personenbezogen agiert.*
In der Menge an Daten, die wir verarbeiten können, ist uns Menschen von vornherein eine Grenze gesetzt. Anfänglich steigt der Wert des Outputs je mehr Daten wir zur Verfügung stellen. Es wird aber bald eine Obergrenze erreicht und wenn dann weitere Angaben einfließen, kann man daraus nicht mehr zusätzlichen Nutzen gewinnen.
Maschinen sind anders. Sie sind in keiner Weise durch die Menge an Daten limitiert, die wir ihnen zuführen. Je mehr Informationen man in sie einspeist, umso mehr wertvolle Ergebnisse können sie produzieren. Abbildung 1.
 Abbildung 1. Big Data & Künstliche Intelligenz. Künstliche Intelligenz ist der Oberbegriff für jede Art Technik, die Computer zu menschenähnlicher Intelligenz befähigt. Darunter fällt Maschinelles Lernen: Rechner lernen indem sie trainiert werden Muster in Datensätzen zu erkennen und Assoziationen zu generieren, die in Form von Algorithmen umgesetzt werden. Deep Learning ist eine Unterform des Maschinellen Lernens, die beispielsweise in der Gesichts- und Spracherkennung eingesetzt wird. Hier erfolgt die Musterkennung in hierarchisch aufgebauten Ebenen eines sogenannten neuronalen Netzwerks. (Text von der Redaktion eingefügt. Bild: modifiziert nach Andrew Ng "What Data scientists should know about Deep Learning" slide 30, in https://www.slideshare.net/ExtractConf).
Abbildung 1. Big Data & Künstliche Intelligenz. Künstliche Intelligenz ist der Oberbegriff für jede Art Technik, die Computer zu menschenähnlicher Intelligenz befähigt. Darunter fällt Maschinelles Lernen: Rechner lernen indem sie trainiert werden Muster in Datensätzen zu erkennen und Assoziationen zu generieren, die in Form von Algorithmen umgesetzt werden. Deep Learning ist eine Unterform des Maschinellen Lernens, die beispielsweise in der Gesichts- und Spracherkennung eingesetzt wird. Hier erfolgt die Musterkennung in hierarchisch aufgebauten Ebenen eines sogenannten neuronalen Netzwerks. (Text von der Redaktion eingefügt. Bild: modifiziert nach Andrew Ng "What Data scientists should know about Deep Learning" slide 30, in https://www.slideshare.net/ExtractConf).
Künstliche Intelligenz - Wie Maschinen lernen
Wir stehen am Beginn eines neuen Zeitalters - einem Zeitalter der maschinellen Intelligenz. Wir schreiten dabei entlang einer aufwärts strebenden Kurve fort. Begonnen hat alles mit einer rein deskriptiven Phase: Daten wurden gelistet und kombiniert. Daran schloss sich eine Phase an, die aus den Daten Schlussfolgerungen ("Inferenzen") generierte. Nun befinden wir uns in einer prädiktiven Phase, d.i. Daten dienen zur Vorhersage zukünftigen Geschehens; von hier wollen wir zu einer präskriptiven Phase kommen - d.i. welche Maßnahmen können getroffen werden, wenn X eintritt? Das Ziel in der Zukunft wird dann eine Kombination von menschlicher und künstlicher Intelligenz sein. Abbildung 2.
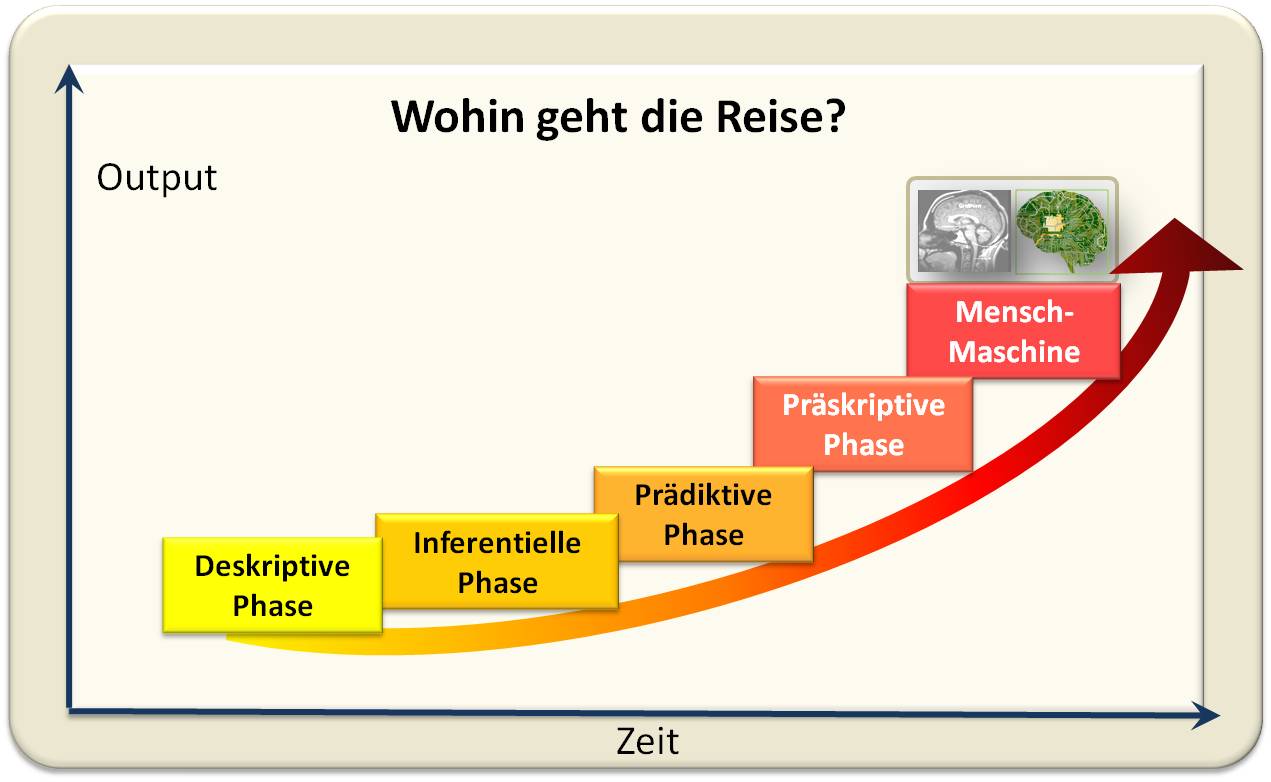 Abbildung 2. Wohin sich die Künstliche Intelligenz entwickelt.
Abbildung 2. Wohin sich die Künstliche Intelligenz entwickelt.
Überwachtes Lernen - Maschinen werden an Hand von Beispielen trainiert
Begonnen hat es mit Big Blue – einem Großrechner von IBM –, der 1996 den damals amtierenden Weltmeister im Schach, Gary Kasparov, schlug. Erstmals besiegte eine Maschine einen überaus routinierten Spieler, zeigte, dass sie im Schach Menschen überlegen war!
Ein zweites Beispiel folgte 2011, als das Computerprogramm Watson als Sieger in der US-Quizsendung Jeopardy hervorging.
Ein weiteres Beispiel lieferte das Google Unternehmen DeepMind (UK), das ein Computerprogramm namens AlphaGo entwickelte und darüber 2016 im Fachjournal Nature publizierte. (Bei dem Spiel Go handelt es sich um ein altes chinesisches Brettspiel , das eine ungleich höhere Zahl an Kombinationen gestattet als das Schach - man schätzt die Zahl der Go-Kombinationen auf 1080, also eine höhere Zahl als es Atome im Universum gibt.) Das System wurde durch Überwachtes Lernen (Human Supervised Learning) trainiert: d.i. man wählte rund 100 000 frühere Go-Spiele als Ausgangspunkt und zeigte, wie die Spieler vorgegangen waren. Die Maschine lernte und besiegte schließlich Nummer 1 auf der Weltrangliste der Go-Spieler. Abbildung 3. 
Abbildung 3. AlphaGo gegen den Go-Champion Lee De-Sol im 3. Match. (Bild: Buster Benson, https://www.flickr.com/photos/erikbenson/25717574115. Lizenz: cc-by-sa)
Weitere Beispiele für derartiges Überwachtes Lernen sind in Spracherkennungssystemen zu finden, wie sie u.a. in Smartphones eingesetzt werden (Siri für Apple-Systeme, Amazon's Alexa für Smartphones und PCs, Google Assistant für Handy, PC, TV, Auto, etc.) und in der Bilderkennung (Hier können Sie beispielsweise Ihr neues iPhone dadurch entsperren, dass es Ihr Gesicht erkennt.) In allen diesen Beispielen wurden die Maschinen mittels "Überwachtem Lernen" trainiert, das heißt, man teilte den Rechnern mit, wie Experten in der jeweiligen Fragestellung zuvor vorgegangen waren.
Unüberwachtes Lernen - Maschinen lernen von alleine
Überaus erstaunlich sind aber Beispiele, in denen Maschinen ohne den Input menschlichen Wissens – d.i. unüberwacht – gelernt haben.
Das erste Beispiel, in dem ein Rechner von der Pike auf lernte, stammt von YouTube. Diese zu Google gehörende Plattform enthält enorm viele Videos: vor etwa fünfeinhalb Jahren schätzte man diese bereits auf rund 800 Millionen Videos; wie viele es heute sind, weiß niemand genau – vermutlich sind es Milliarden. Man stellte nun an den Rechner die Frage: "Welches Bild kommt am häufigsten in Youtube-Videos vor?".
Nun hatte der Computer a priori keine Ahnung, wie Dinge eigentlich aussehen - er musste überhaupt erst lernen, was ein Bild ist. Selbst im Management von Google zeigte man sich recht skeptisch, ob eine derartige Frage mittels Künstlicher Intelligenz zu lösen wäre. Das Ergebnis bekehrte die Zweifler. Die Antwort auf die Frage lautete: es sind dies Katzen. Abbildung 4.
Wir alle wissen natürlich, wie eine Katze aussieht - sie hat Barthaare, vier Pfoten, zwei Ohren, etc. Der Computer musste sich all diese Charakteristika erst selbst beibringen. Er fand heraus: so sieht eine Katze aus; dazu kam noch, dass er Katzen in den verschiedensten Positionen erkannte - stehend, liegend, springend, etc.
 Abbildung 4. Welches Bild kommt in den mehr als eine Miliiarde YouTube Videos am Häufigsten vor?
Abbildung 4. Welches Bild kommt in den mehr als eine Miliiarde YouTube Videos am Häufigsten vor?
Ein weiteres Beispiel , das kürzlich aufschien, hieß AlphaGo-Zero. Es ging hier wiederum um ein Programm für das Go-Spiel, allerdings fehlte dem Computer jeglicher Input zuvor erfolgter menschlicher Erfahrungen. Man ging von einer Tabula rasa, also von einem leeren Blatt Papier, aus. Basierend auf selbst-verstärkendem Lernen war AlphaGo-Zero sein eigener Lehrer und der Computer spielte drei Tage gegen sich selbst. Das Ergebnis war, dass AlphaGo-Zero den Weltmeister - einen Koreaner namens Lee Se-Dol - besiegte, von insgesamt 100 Spielen gewann der Computer alle Spiele.
Es ist einfach unglaublich, was Computer können und wohin Künstliche Intelligenz uns führen wird.
Deep Learning in der Medizin
Die erste Anwendung von Deep Learning, die in die Medizin voll Eingang gefunden hat, ist die medizinische Bildverarbeitung. Vier Veröffentlichungen aus dem letzten Jahr (für 2017 listet die Literaturdatenbank PubMed insgesamt 277 Arbeiten zu dem Thema auf; Anm. Redn.) zeigen ein breites Spektrum der Anwendungen: so geht es darin um hoch spezifische und sensitive Erkennung von Retinopathien, um die automatische höchst spezifische Diagnose von Lungentuberkulose, um die Erkennung von Arrhythmien, welche die Erfolgsrate von Kardiologen bereits übertrifft und um die Klassifizierung von Hauttumoren, die es mit Leistung aller Experten aufnehmen kann.
Können Computer auch neurologische Krankheiten erkennen?
Eine kürzlich in Neuroscience & Behavioral Reviews (Vieira et al., 2017) erschienene Arbeit hält Deep Learning für ein leistungsfähiges Instrument in der aktuellen Forschung zu psychiatrischen und neurologischen Erkrankungen. Eine Reihe von Unternehmen in der Bay Area von San Francisco arbeitet bereits in diesem Gebiet; so analysiert eine dieser Firmen (Mindstrong Health, Anm. Redn) die Art und Weise, wie wir das Handy benutzen - - d.i. wann man das Handy berührt, wie man es berührt, was man damit dann tut, wie man e-mails verfasst, wie man Texte schreibt, etc. - und erstellt daraus Algorithmen, um Depressionen zu erkennen.
Wohin führt diese Entwicklung?
Vor rund einem Jahr hat Verily (eine den Lebenswissenschaften gewidmete Tochter von Alphabet, wie Google jetzt heißt) zusammen mit der Duke University School of Medicine und Stanford Medicine die Studie Baseline gestartet. Rund 10 000 Personen nehmen an der über vier Jahre laufenden Studie teil, deren Ziel das Verstehen und Vermessen der menschlichen Gesundheit (Understanding and Mapping Human Health) ist.
Die Baseline-Studie – wie wird eigentlich Gesundheit definiert?
Die Idee dahinter ist von jedem Teilnehmer alles zu bestimmen, was nur denkbar ist: also das gesamte Genom zu sequenzieren, Proteom & Mikrobiom zu analysieren, Signalmoleküle (Cytokine) zu erfassen, diverse Gesundheitsparameter zu messen, das allgemeine Befinden und den Lebensstil zu erfassen, usw. Zu einer kontinuierlichen Bestimmung werden u.a. Wearables verwendet, die wie eine Uhr aussehen und ständig Blutdruck und Puls messen, oder auch Kontaktlinsen, die den Glukosespiegel in den Tränen messen. Abbildung 5. 
Abbildung 5. Was ist Gesundheit? Was wird gemessen? Die Baseline-Studie von Verily (Bild: cc Verily, https://www.projectbaseline.com/)
Diese Bestimmungen werden nun Milliarden und Abermilliarden Daten generieren. Auf Basis dieser Big Data sollen mittels Deep Learning zwei Ziele erreicht werden:
- Es soll eine Basislinie der Gesundheit festgelegt werden, (was als gesund und nicht gesund betrachtet wird, hängt dabei von der Zusammensetzung der Population ab - beispielsweise korreliert bei älteren Menschen ein niedriger Blutdruck mit einer erhöhten Mortalität, ist daher nicht immer positiv zu sehen).
- Es sollen Vorhersagen für die Entwicklung des Gesundheitszustandes getroffen werden. Anstatt darauf zu warten, dass etwas passiert, kann man ein Risikoprofil erstellen, und daraus ableiten, wie hoch das Risiko ist, das man - in welchem Fall - auch immer hat.
Fazit
Künstliche Intelligenz führt uns weg von der gegenwärtigen Medizin, die sporadisch und reaktiv ist, d.i. einer Medizin, die erst reagiert, wenn etwas bereits "passiert" ist. Die Medizin wird sich vielmehr komplett in eine kontinuierlich verfolgbare, vorausschauende - proaktive - Form verwandeln, die personenbezogen agiert und rechtzeitig Risiken erkennt und diesen vorbeugt.
* Dies ist der zweite Teil einer Artikelserie des Autors, die sich im Teil 1 "Auf dem Weg zu einer Medizin der Zukunft" mit dem sich abzeichnenden Paradigmenwechsel in der Medizin – Abgehen von Therapien nach dem Schema "Eine Größe passt allen" hin zu einer zielgerichteten, personalisierten Behandlung - befasst hat (http://scienceblog.at/auf-dem-weg-zu-einer-medizin-der-zukunft#). Beispiele für "Personalisierte Medizin" sollen im dritten Teil an Hand der CAR-T Zell Therapie aufgezeigt werden. Über das gesamte Thema hat Norbert Bischofberger am 6. Dezember 2017 einen Vortrag "The future of medicine: Technology and personalized therapy" in der Österreichischen Akademie der Wissenschaften gehalten.
Weiterführende Links
Christopher Nguyen Algorithms of the Mind. https://arimo.com/featured/2015/algorithms-of-the-mind/
New DeepMind AI Beats AlphaGo 100-0 | Two Minute Papers #201, Video 5:52 min (30.10.2017). https://www.youtube.com/watch?v=9xlSy9F5WtE
AlphaGo Zero: Learning from scratch. https://deepmind.com/blog/alphago-zero-learning-scratch/
Project Baseline (Verily). https://www.projectbaseline.com/; Video 1:17 min https://www.youtube.com/watch?v=ufOORB6ZNaA Standard-YouTube-Lizenz
Jürgen Schmidhuber: Vortrag „Künstliche Intelligenz wird alles ändern“ 2016, Video 49:17 min. https://www.youtube.com/watch?v=rafhHIQgd2A
Artikel im ScienceBlog
Francis S. Collins, 26.04.2018: Deep Learning: Wie man Computern beibringt, das Unsichtbare in lebenden Zellen zu "sehen". http://scienceblog.at/deep-learning-wie-man-computern-beibringt-das-unsichtbare-lebenden-zellen-zu-sehen.
Gerhard Weikum, 20.06.2014: Der digitale Zauberlehrling. http://scienceblog.at/der-digitale-zauberlehrling.
Peter Schuster, 28.03.2014: Eine stille Revolution in der Mathematik. http://scienceblog.at/eine-stille-revolution-der-mathematik.
- Printer-friendly version
- Log in to post comments