Die Großhirnrinde verarbeitet Information anders als künstliche intelligente Systeme
Die Großhirnrinde verarbeitet Information anders als künstliche intelligente SystemeDo, 05.12.2019 — Wolf Singer

![]()
Bereits heute übertreffen künstliche intelligente Systeme in einigen Bereichen die Leistungen des menschlichen Gehirns. In natürlichen Systemen, vor allem in der Großhirnrinde, sind jedoch Verarbeitungsstrategien verwirklicht, die sich in wesentlichen Aspekten von denen künstlicher Systeme unterscheiden. Ein besseres Verständnis natürlicher intelligenter Systeme kann zur Aufklärung der Ursachen von krankheitsbedingten Störungen beitragen und zudem die Konzeption wesentlich effizienterer künstlicher Systeme erlauben. Diese natürlichen intelligenten Systeme besser zu verstehen ist das zentrale Anliegen eines der renommiertesten Hirnforscher Prof. Dr.Dr.hc.mult Wolf Singer (Max-Planck-Institut für Hirnforschung und Ernst Strüngmann Institut für Neurowissenschaften, Frankfurt)*
Bereits heute übertreffen in manchen Bereichen die Leistungen künstlicher intelligenter (KI-) Systeme die von biologischen Systemen. Viele der effizientesten KI-Algorithmen orientieren sich an neuronalen Systemen, doch die Hirnforschung liefert Hinweise dafür, dass in natürlichen Systemen, vor allem in der Großhirnrinde, zusätzliche Verarbeitungsstrategien Anwendung finden, die sich von denen derzeitiger KI-Systeme grundlegend unterscheiden. Die meisten KI-Systeme beruhen auf den in den achtziger Jahren des letzten Jahrhunderts eingeführten „neuronalen Netzen“. Deren Architektur ist in Abbildung 1 skizziert.
 Abbildung 1. Architektur eines „deep learning networks“: Die Knoten dieser Netze bestehen aus Schaltelementen, die gewisse Merkmale von Nervenzellen aufweisen - sie summieren die Aktivität der Eingangsverbindungen und geben das Ergebnis an die Knoten nachfolgender Verarbeitungsschichten weiter. © Ernst-Strüngmann-Institut/Singer
Abbildung 1. Architektur eines „deep learning networks“: Die Knoten dieser Netze bestehen aus Schaltelementen, die gewisse Merkmale von Nervenzellen aufweisen - sie summieren die Aktivität der Eingangsverbindungen und geben das Ergebnis an die Knoten nachfolgender Verarbeitungsschichten weiter. © Ernst-Strüngmann-Institut/Singer
Jeder Knoten der Eingangsschicht ist mit vielen Knoten der nächsthöheren verbunden. Die ersten KI-Systeme umfassten nur drei Schichten: eine Eingangsschicht, eine mittlere Schicht („hidden layer“ genannt), deren Aktivität nicht direkt zugänglich sein muss, und eine Ausgangsschicht, die die Aktivitätsverteilung der mittleren Schicht ausliest. Heute sind die leistungsstärksten Netze bis zu hundert Schichten tief. Die besondere Schwierigkeit besteht darin, die Gewichtung der Verbindungen über Millionen von Lernschritten so einzustellen, dass jedes der zu unterscheidenden Eingangsmuster in der Ausgangsschicht zu einem leicht klassifizierbaren Erregungsmuster führt.
Damit solche Netzwerke z. B. zur Mustererkennung eingesetzt werden können, muss man dafür sorgen, dass ein bestimmtes Erregungsmuster der Eingangsschicht zur bevorzugten Erregung eines ganz bestimmten Knotens der Ausgangsschicht führt. Hierzu werden an der Eingangsschicht viele Muster erzeugt und es wird versucht, die Effizienz der Verbindungen zwischen den Schichten durch wiederholte Justierung schrittweise zu verbessern. Je nach Anzahl der zu unterscheidenden Muster und deren Ähnlichkeit kann dies viele Millionen von Justierungs- bzw. Lernschritten erfordern. Hierbei werden die Verbindungen ermittelt, deren Aktivität zu dem gewünschten Ergebnis beiträgt. Diese werden dann verstärkt und die anderen abgeschwächt. Es wird also die Abweichung vom gewünschten Ergebnis, der Fehler, in das Netzwerk zurückgemeldet. Dieser Prozess (back propagation genannt) ist extrem aufwändig und hat in biologischen Systemen keine Entsprechung.
Heutige künstliche Systeme beruhen auf dem gleichen Grundprinzip, umfassen jedoch bis zu 100 Schichten und werden deshalb als „deep learning networks“ bezeichnet. Beherrschbar ist diese riesige Zahl von Verbindungen zwischen den Schichten dank ausgeklügelter Algorithmen, welche die Justierung vornehmen, und dank riesiger Rechenkapazitäten und Datenbanken, die es erlauben, die Systeme mit Millionen von Beispielen zu trainieren.
In natürlichen Systemen sind Netzwerkknoten innerhalb einer Schicht und zwischen den Schichten reziprok miteinander verbunden
Charakteristisch für diese künstlichen Netze ist, dass es keine Verbindungen zwischen den Knoten innerhalb der gleichen Schichten gibt und der Aktivitätsfluss stets nur von den niederen zu den hohen Schichten erfolgt. Wie jedoch Abbildung 2 zeigt, unterscheiden sich künstliche Systeme von den natürlichen in genau diesen Aspekten: Die Knoten einer Schicht stehen über Myriaden von Verbindungen miteinander in Wechselwirkung und der Aktivitätsfluss zwischen den Schichten erfolgt in beiden Richtungen.
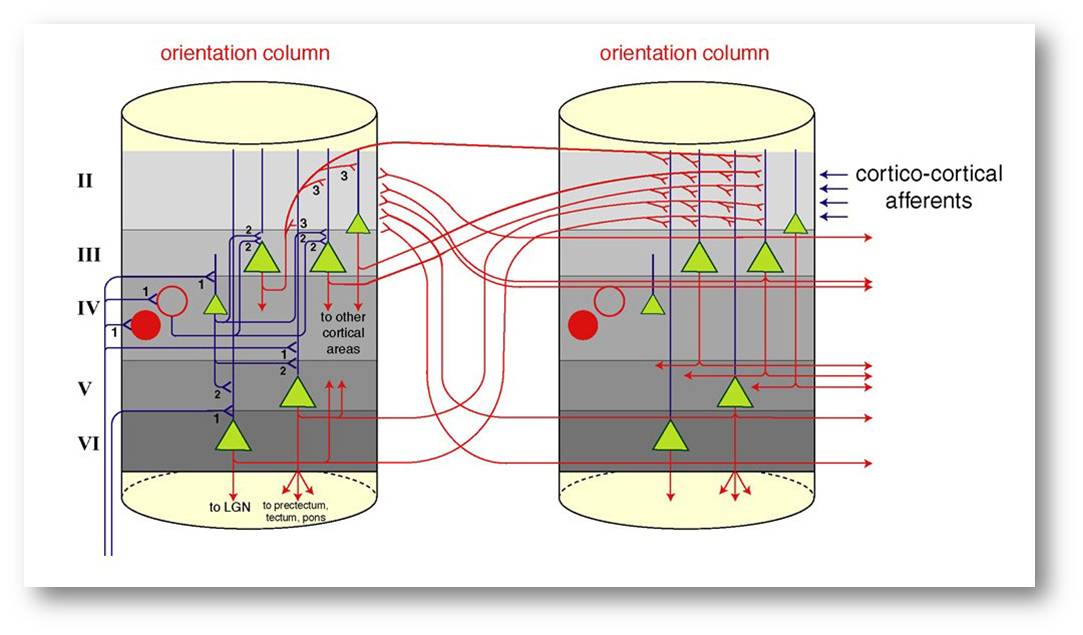 Abbildung 2. Stark vereinfachtes Diagramm der Verschaltung von Nervenzellen in der Großhirnrinde. Hier bestehen die Knoten des Netzwerkes aus Modulen von bereits sehr komplexen Schaltkreisen. Diese sind ihrerseits über Myriaden von rekurrierenden Verbindungen (rot) untereinander und über Rückkopplungsschleifen mit den Knoten der vorherigen Schicht gekoppelt. Somit erfolgt der Aktivitätsfluss sowohl horizontal wie vertikal in beiden Richtungen. © Ernst-Strüngmann-Institut/Singer
Abbildung 2. Stark vereinfachtes Diagramm der Verschaltung von Nervenzellen in der Großhirnrinde. Hier bestehen die Knoten des Netzwerkes aus Modulen von bereits sehr komplexen Schaltkreisen. Diese sind ihrerseits über Myriaden von rekurrierenden Verbindungen (rot) untereinander und über Rückkopplungsschleifen mit den Knoten der vorherigen Schicht gekoppelt. Somit erfolgt der Aktivitätsfluss sowohl horizontal wie vertikal in beiden Richtungen. © Ernst-Strüngmann-Institut/Singer
In biologischen Systemen wird die Effizienz der Verbindungen nach lokalen Regeln justiert. Nervenzellen dienen als Knoten, die viel mehr leisten, als Eingangsaktivitäten zu summieren. Ihre integrativen Eigenschaften werden durch komplizierte hemmende Schaltkreise und zudem durch eine Vielzahl modulierender Eingänge abhängig von der jeweiligen Aufgabenstellung verändert. Auch können die Knoten oszillieren und sich wegen der wechselseitigen Koppelungen in unterschiedlichen Frequenzbereichen synchronisieren. Auf Grund dieser Eigenschaften entwickeln die Neuronen-Netze der Großhirnrinde eine hochkomplexe, nicht-lineare Dynamik, die es erlaubt, sehr hochdimensionale Zustandsräume zu erschließen.
Mit diesen Eigenschaften natürlicher Neuronen-Netze können Rechenoperationen verwirklicht werden, die in bisherigen KI-Systemen nur mit sehr großem Aufwand zu realisieren sind: zeitlich aufeinander folgende Ereignisse lassen sich problemlos miteinander verrechnen, Bezüge zwischen bestimmten Mustermerkmalen können sehr flexibel kodiert werden und wegen der hohen Dimensionalität der Netzwerkdynamik kann mit relativ geringem Aufwand eine sehr große Menge an Information gespeichert werden. Auf diese Weise kann über die aktivitätsabhängige Justierung der Effizienz der reziproken Verbindungen eine riesige Menge von Informationen gespeichert und dasselbe Netzwerk dann zur Interpretation von Sinnessignalen verwendet werden.
Um unser Konzept zu überprüfen, müssen wir die Aktivität einer möglichst großen Zahl von Netzwerkknoten erfassen, Kenngrößen für deren dynamische Wechselwirkungen berechnen und bestimmen, wie diese sich verhalten, wenn gespeichertes „Vorwissen“ mit der jeweils verfügbaren Sinnesinformation verglichen wird. Wir nehmen diese Messungen an nicht-menschlichen Primaten vor, die gelernt haben, visuelle Muster zu unterscheiden, zu erinnern und uns durch Tastendruck das Ergebnis mitzuteilen – ähnlich wie Computerspieler. Während die Tiere die Aufgaben erledigen, erfassen wir mit dauerhaft implantierten Elektroden die Aktivität von Neuronen der Sehrinde. Die Implantation erfolgt in Vollnarkose und läuft genau wie die Implantation von Elektroden bei menschlichen Patienten ab. Die Messungen selbst sind für die Tiere nur wenig belastend und können in der Regel über viele Jahre hinweg ohne weitere Eingriffe vorgenommen werden.
Ausblick
Wir erhoffen uns von diesen Arbeiten ein tieferes Verständnis der neuronalen Prozesse, die unseren kognitiven und exekutiven Leistungen zu Grunde liegen. Unsere Überzeugung ist, dass diese Erkenntnisse den Schlüssel für das Verständnis der Ursachen gestörter neurologischer und psychischer Funktionen und für zukünftige therapeutische Ansätze bergen. Um hier Fortschritte zu erzielen, bedarf es jedoch noch erheblicher Anstrengungen in der Grundlagenforschung. Auch ist zu erwarten, dass ein tieferes Verständnis der Großhirnrindenfunktion dazu beitragen wird, energieeffizientere und flexiblere KI-Systeme zu entwickeln. Hierfür sind jedoch neue Technologien erforderlich. Es genügt nicht, neuronale Prozesse mit gewaltigem Aufwand digital zu simulieren. Sie müssen direkt in geeigneten Hardware-Modulen implementiert werden, die auch analoge Rechenvorgänge verlässlich bewältigen können.
*Der unter dem Titel "Informationsverarbeitung in der Großhirnrinde" im Jahrbuch der Max-Planck Gesellschaft 2018 erschienene Artikel (https://www.mpg.de/12587759/esi-frankfurt_jb_2018?c=917421 DOI 10.17617/1.7M ) wurde mit freundlicher Zustimmung des Autors und der MPG-Pressestelle ScienceBlog.at zur Verfügung gestellt. Er erscheint hier ungekürzt aber ohne Literaturzitate, die im Original nachgesehen werden können
Weiterführende Links
- Interview mit Wolf Singer - Physik und Biologie wachsen zusammen. HyperraumTV, (24.10.2016) Video 15:30 min.
- AIL-Talk: Wolf Singer - Neuronale Grundlagen des Bewusstseins. Video 1:29:27 from Angewandte Innovation Lab. 07.09.2016
Artikel im ScienceBlog
- Wolf Singer, 16.12.2016: Die Großhirnrinde, ein hochdimensionales, dynamisches System.